Abstract
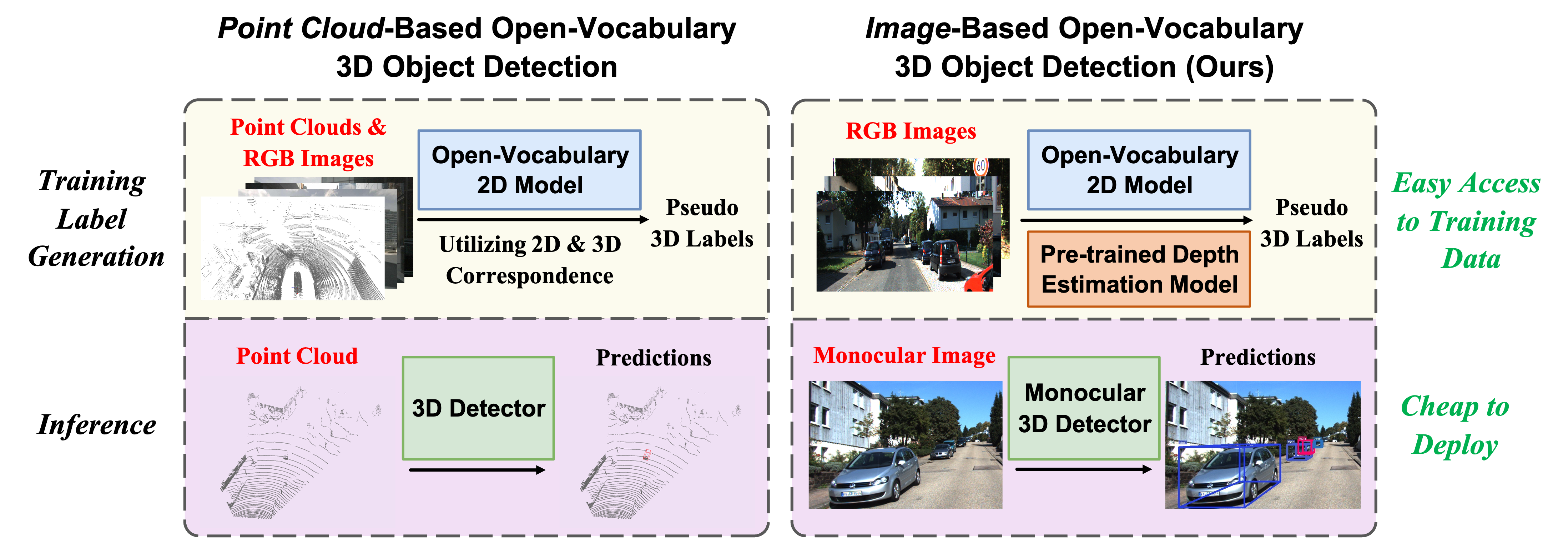
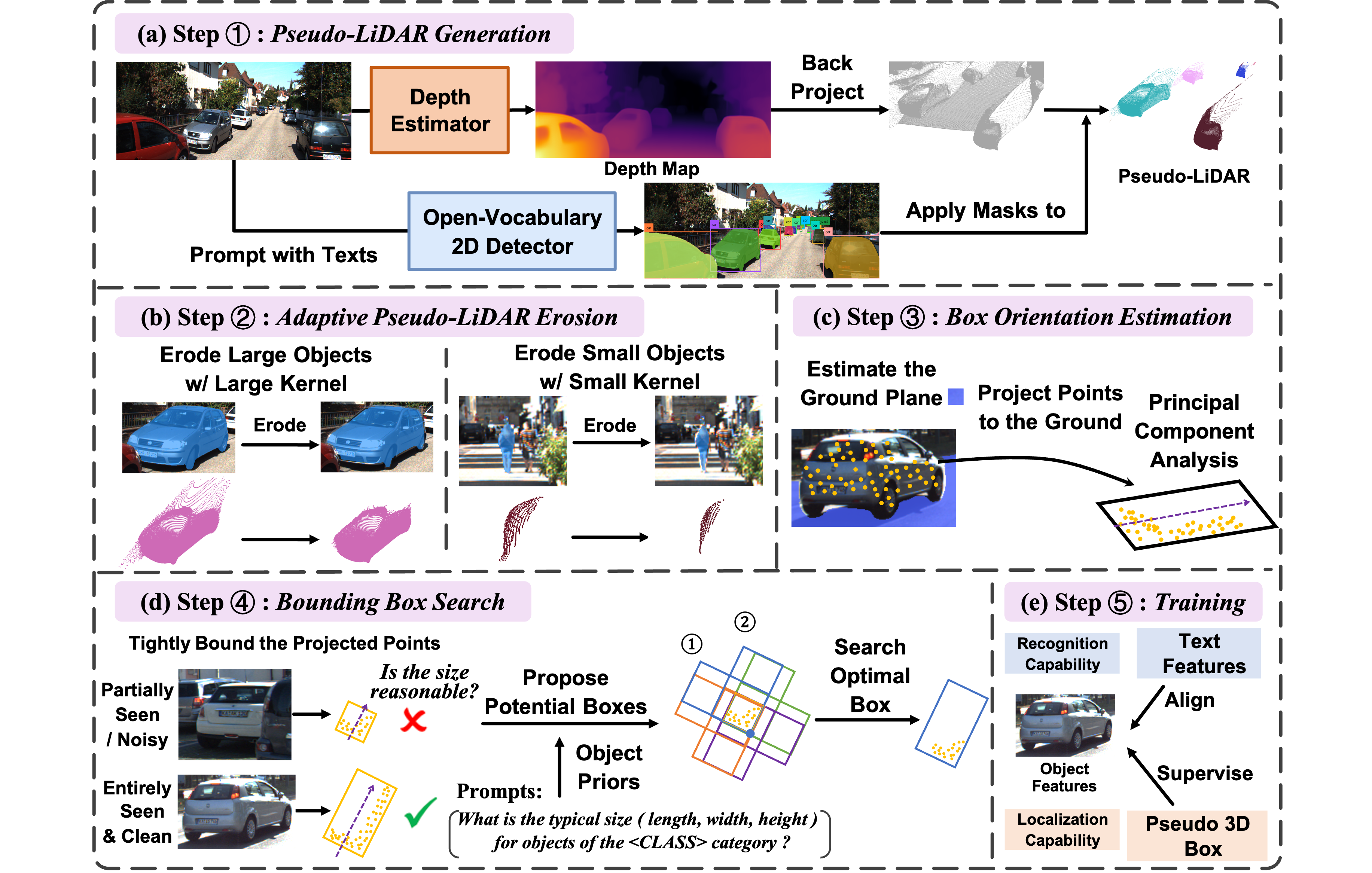
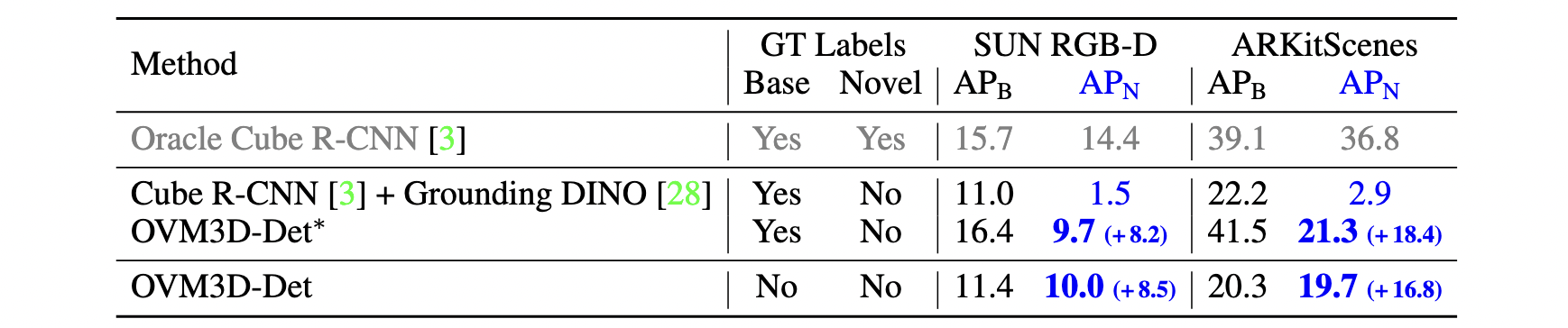
Open-vocabulary 3D object detection has recently attracted considerable attention due to its broad applications in autonomous driving and robotics, aiming to recognize novel classes in previously unseen domains. However, existing point cloud-based models are limited by their high deployment costs. In this work, we propose a novel open-vocabulary monocular 3D object detection framework, dubbed OVM3D-Det, which trains detectors using only RGB images, making it both cost-effective and scalable to publicly available data. Unlike traditional methods, OVM3D-Det does not require high-precision LiDAR or 3D sensor data for either input or generating 3D bounding boxes. Instead, it employs open-vocabulary 2D models and pseudo-LiDAR to automatically label 3D objects in RGB images, fostering the learning of open-vocabulary monocular 3D detectors.